{kind=link}
บทสรุปนี้เป็นส่วนหนึ่งของโครงการ Super AI Engineer และเนื้อหาจาก อ.เอกพล จากคณะวิศวกรรมคอมพิวเตอร์ มหาวิทยาลัยจุฬาลงกรณ์ ต้องขอขอบคุณทางโครงการและอาจารย์เป็นอย่างสูงด้วยครับ
ภาคเช้า
Machine learning หลักๆแบ่งตามการเรียนรู้ได้ 3 ประเภท
- Supervise Learning (เรียนรู้จากข้อมูลที่มี x,y)
- Unsupervise Learning (หา structure ในข้อมูลที่มีแค่ x)
- Reinforcement Learning
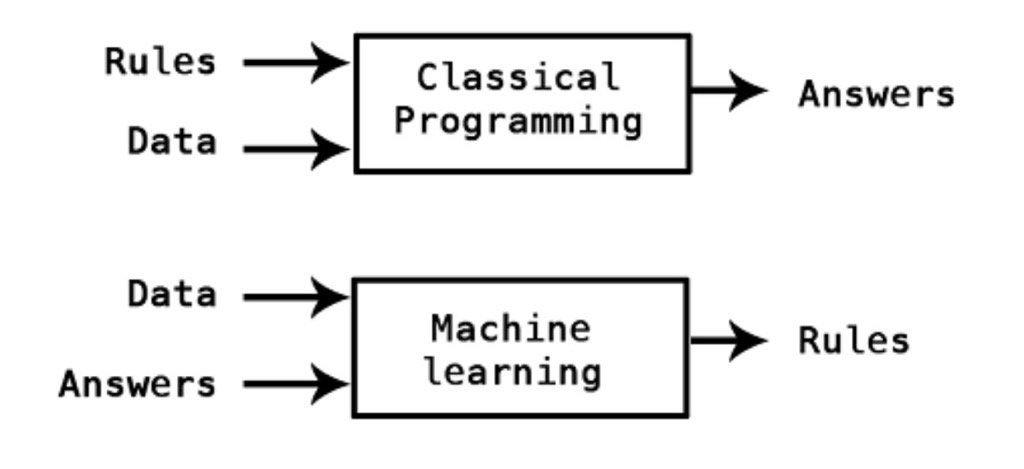
ก่อนที่จะมีการใช้ machine learning เราใช้ rule-base ในการหาผลลัพท์เพื่อหาความสัมพันธ์ ซึ่งในการใช้งานบางทีข้อมูลมีจำนวนมาก ทำให้การใช้งาน rule-base จะทำได้ลำบาก
การสร้างกฎหรือเงื่อนไขอย่างง่าย (rule base)
ตัวอย่างการใช้งาน rule-base เช่น การเขียนโปรแกรมควบคุมไฟแสดงตัวเลข จะเห็นได้ว่าความสัมพันธ์ จะเป็นในรูปแบบของฟังก์ชัน F(x) โดย a,b,c,d,e,f,g ก็คือ x โดยมีค่าเป็น 0,1 (ไฟดับ,ไฟติด) และ y คือ 0-9 ซึ่งจะเขียนโปรแกรมได้ตัวอย่างในรูป
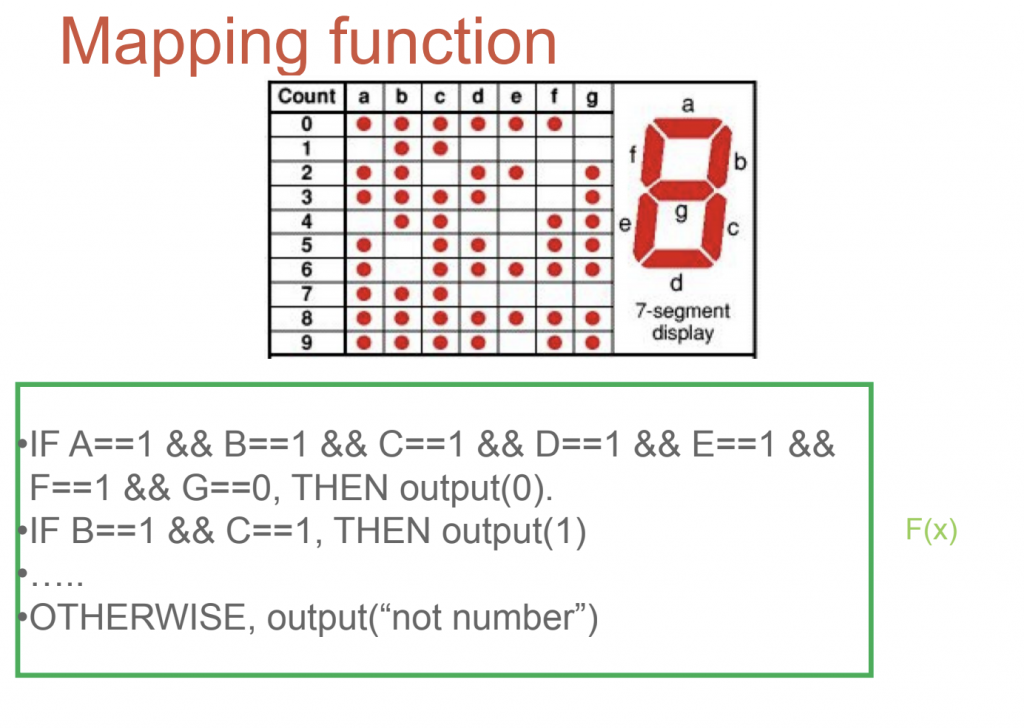
จะเห็นได้ว่าเงื่อนไขมีไม่มาก เราสามารถใช้ rule-base มาแก้ไขได้ ซึ่งในความเป็นจริงข้อมูลจะมีมากและซับซ้อนกว่านี้ เช่น การทำนายราคาหุ้น การแยกแยะรูปภาพว่าใช่หรือไม่ใช่ เราจึงนำ machine learning มาช่วยโดยการส่ง input เข้าไป เพื่อหาความสัมพันธ์ออกมา โดย input เป็นได้หลายแบบ รูปภาพ,อุณหภูมิ,หรือข้อมูลที่มาจาก sensor อื่นๆก็ได้
โจทย์ต่อมา ไปรษณีย์อเมริกาต้องการแยกจดหมายแบบอัตโนมัติ โดยแยกจากรหัสไปรษณีย์ โดย input จะเป็นตัวเลขที่เป็นตัวเขียนบนหน้าซองจดหมาย และ output เป็น 0-9 ลักษณะคล้ายกับตัวอย่างแรก จะเห็นว่าเราจะทำแบบแยกเงื่อนไขเหมือนเดิมไม่ได้ ด้วยเหตุนี้จึงต้องใช้ machine learning มาช่วยหาฟังก์ชันที่ดีที่สุด โดยเป็นการหาแบบอัตโนมัติจากข้อมูลที่มี และนี่จึงเป็นที่มาของ Supervise learning


Supervise Learning คือ เราต้องการที่จะหาฟังก์ชัน F หรือ classifier ซึ่งจะเรียนรู้จาก trainning sets ในตัวอย่างนี้จะเป็น (x1,y1),(x2,y2),…,(xn,yn)

ซึ่งการหา F(x) ที่ดีที่สุด เราจะเรียกว่า optimization และการที่เราเตรียมชุดข้อมูล x,y เราเรียกว่า labeling โดยทำได้ทั้งแบบ manuals หรือ semi manuals แบบ semi คือ ให้โมเดลตอบก่อนและคนมาแก้ไขเพิ่มเติม
ขั้นตอนการทำงานของ machine learning (work flow)
- Feature Extraction การหาค่า x
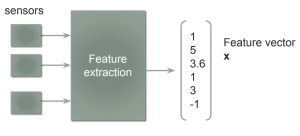
การแปลงข้อมูลให้อยู่ในรูปของตัวเลข เพื่อนำไป train โดยถือว่าเป็นส่วนที่สำคัญเพราะถ้าข้อมูลไม่ดีผลที่ได้ก็จะไม่ดี ดังนั้น จึงมีการวิเคราะห์และทำความสะอาดข้อมูลก่อนที่จะนำไปใช้งาน
- Modeling
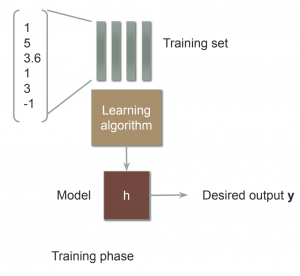
การนำข้อมูลมาหาความสัมพันธ์ในรูปของสมการ โดยฟังก์ชันที่ได้มาจะเรียกว่า model ซึ่งโมเดลนี้จะนำข้อมูล test มาทำนายผลเพื่อเปรียบเทียบวัดผลได้
- Evaluation
การวัดผล โดยทั่วไปจะมีดังนี้
Error rate, Accuracy rate, Precision, True positive, Recall, False Alarm, F score
Regression
ตัวอย่างการทำนายราคาบ้าน
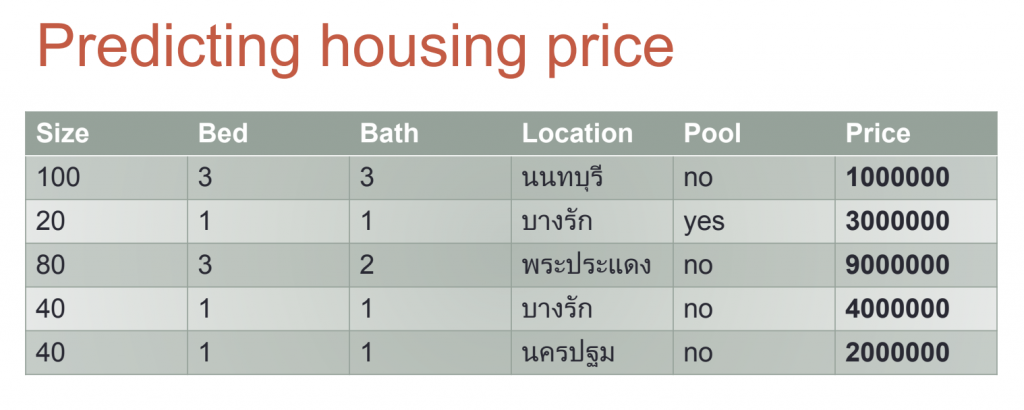
เราต้องแปลงข้อมูลให้อยู่ในรูปของตัวเลข โดยแปลง Location อาจจะใช้ label encoding และแปลง pool อาจจะใช้ one hot encoding จากนั้นหาสมการหรือโมเดล
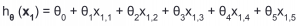
สมการนี้เรียกว่า linear regression ก็คือ สมการเส้นตรง regression คือหาค่าที่ได้เป็นตัวเลข ถ้าเป็น classification ค่าที่ได้จะเป็น category โดยที่ θ คือ weight
การทำงานในการหา model จะเริ่มจากการ random ค่า weight และหาค่าที่ดีที่สุด โดยการที่จะหาค่าที่ดีที่สุดได้ เราจึงต้องมีการวัดผลของแต่ล่ะสมการหรือฟังก์ชัน โดยวิธีการคือใช้ Cost function (Loss function)
Cost function (Loss function)

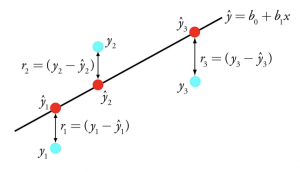
loss function ตัวอย่างเช่น MSE ซึ่งคือผลรวมของค่าความผิดพลาดของ model ดังนั้น การที่เราจะหาค่า θ ที่ดีที่สุด คือการทำให้ loss function มีค่าน้อยที่สุด
Gradient descent
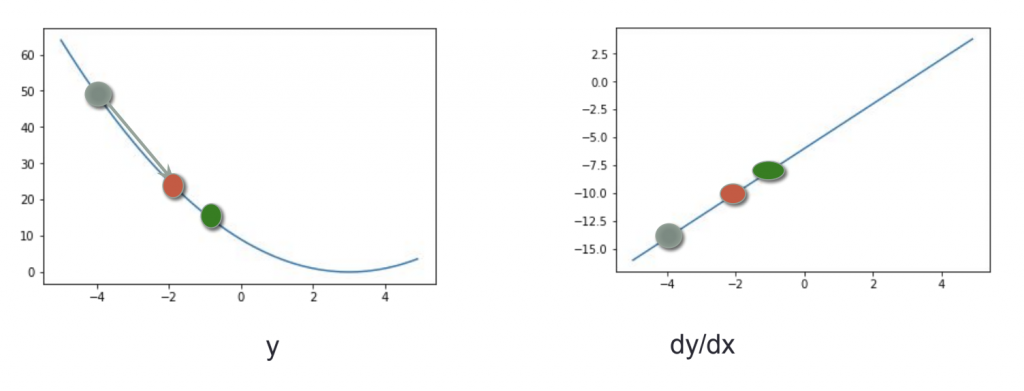
เป็นวิธีการหาค่าที่ดีที่สุด ด้วยการ dy/dx ซึ่งก็คือค่าความชันของสมการ
ถ้าความชันเป็นลบ เพิ่ม x ก็จะลด y ทิศทางจะวิ่งลง
ถ้าความชันเป็นบวก เพิ่ม x ก็จะเพิ่ม y ทิศทางจะวิ่งขึ้น
โดยทิศทางจะวิ่งไปทางที่ค่าความชันเข้าใกล้ 0 ถ้าวิ่งเกินไปก็จะวิ่งย้อนกลับ ทำแบบนี้จนได้ค่าที่ดีที่สุด
Learning Rate
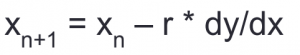
การเคลื่อนที่ x จะเป็นดังสมการข้างต้น ซึ่งจะมี r เป็นค่า learning rate ซึ่งจะเป็นตัวกำหนดการก้าวเดินว่าเคลื่อนมากหรือน้อย ซึ่งมีผลต่อการหาความชันที่จุดต่ำสุด ถ้าก้าวมากเกินไปก็อาจจะข้ามจุดต่ำสุดไปมาโดยลงไม่ถึงจุดต่ำสุด แต่ถ้าก้าวน้อยเกินไปก็อาจจะเข้าสู่จุดต่ำสุดได้ช้า ขึ้นกับการพิจารณา
สมการปรับค่า θ (gradien descent)
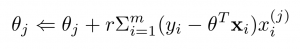
จะเห็นได้ว่าในสมการจะมี xi^j ซึ่งส่วนนี้ คือ feature และในวงเล็บคือ error จะเห็นได้ว่า feature จะมีผลต่อการก้าวเดิน ซึ่งถ้าข้อมูลมีขนาดต่างกันเยอะ ทำให้การก้าวเดินจะลำบาก ดังนั้นส่วนใหญ่จึงต้องทำการ normalize ข้อมูล
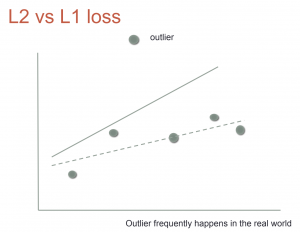
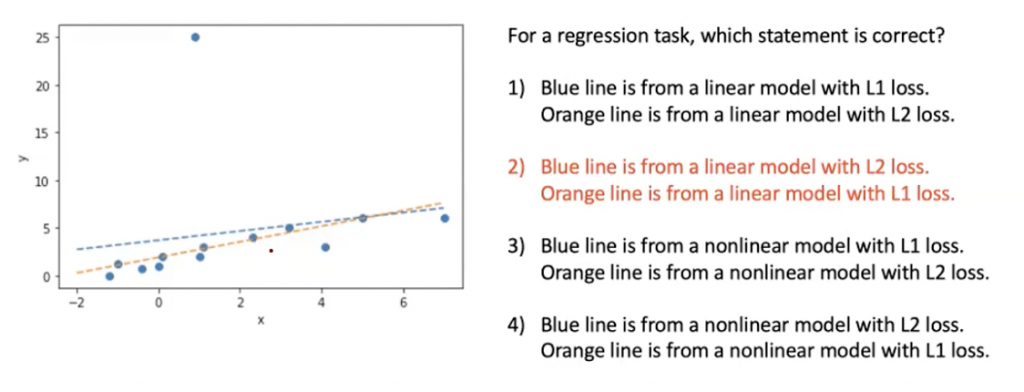
L1 Loss , L2 Loss (MSE)
เลข 1,2 มาจากเลขยกกำลังของสมการ
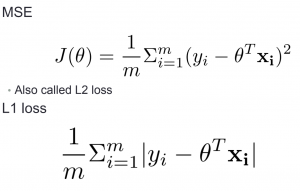
กรณีที่มี outlier จะส่งผลให้เส้น model มีการเปลี่ยนตำแหน่งที่ผิดไป ซึ่ง L2 จะมีผลมากกว่าสำหรับข้อมูลที่มี outlier เพราะสมการยกกำลังสอง ทำให้มีการเปลี่ยนแปลงมากกว่า L1 วิธีการแก้ไขคือให้เปลี่ยน loss function ไปใช้ L1 แทน
Overfitting Underfitting
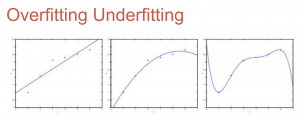
จากในรูปภาพแรกคือ underfitting ภาพสองคือโมเดลที่เหมาะสม ภาพสามคือ overfitting
overfitting คือ การที่ model ทำนายผลได้แม่นยำกับ training set แต่ทำนายผลได้แย่กับ test set ซึ่งเกิดจากการที่เรามี feature มากเกินไป หรือ ใช้ polynomial อันดับสูงเกินไป
วิธีแก้ไข underfitting
underfitting แก้ไขได้ด้วยการเพิ่ม feature หรือหาข้อมูลมาเพิ่ม หรือใช้ model ที่มีความซับซ้อนมากๆ
วิธีแก้ไข overfitting
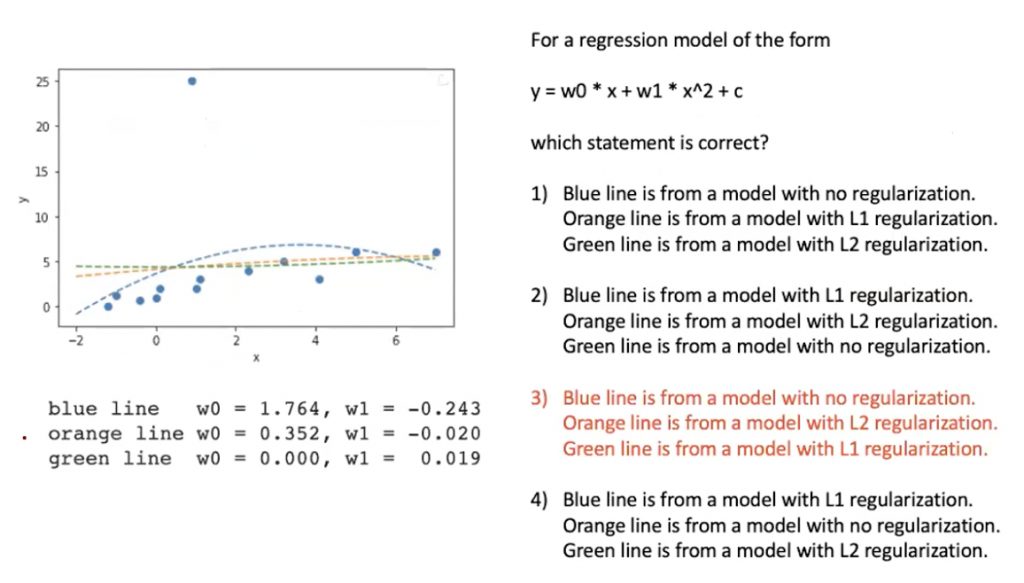
1. ลดจำนวน feature หรือใช้ model selection algorithm
2. ใช้ regularization เพื่อทำให้เราไม่ต้องลด feature
เราจะเพิ่ม regularization เข้าไปในสมการ loss function เพื่อควบคุมทำให้ weight นั้นมีขนาดเล็กลง
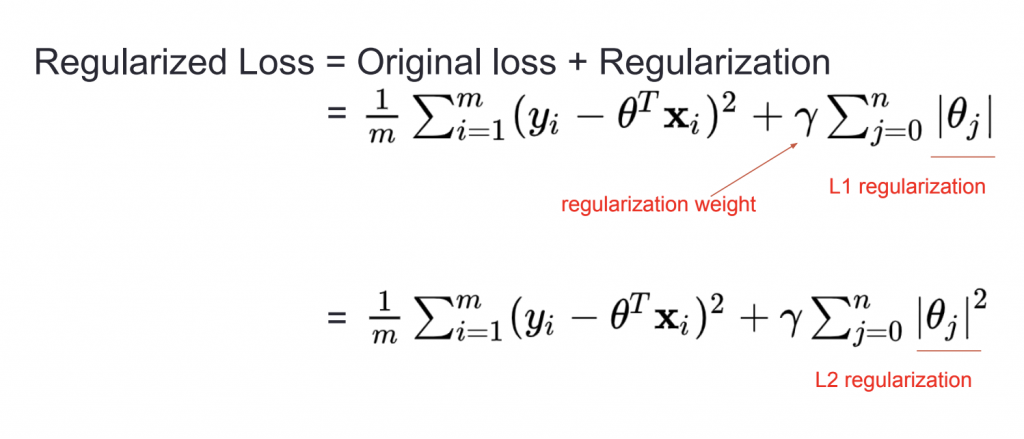
regularization weight เป็นค่าที่ปรับได้ ถ้ามีค่ามากก็จะยิ่งเกลี่ยค่า weight ในแต่ล่ะ feature มากขึ้น
L1 regularization จะทำให้ feature เป็น 0 จำนวนมาก โดยการลด weight ซึ่งจะเป็นการลด feature เหมือนการทำ feature selection
L2 regularization จะเป็นการเกลี่ยค่า โดยลดค่า weight ไปยังแต่ล่ะ feature โดยจะพยายามลด weight ที่มีค่ามากๆ
Linear regression ที่มีการใช้ regularization
Ridge regression: regression with L2 regularization
Lasso regression: regression with L1 regularization
ElasticNet regression: regression with L1 and L2
regularization
การใช้งาน model สำเร็จรูปจะปรับ regularization weights ได้ โดยถ้าเพิ่มค่าจะช่วยลด overfitting ได้
การ prediction แบบ categorical (binary classification)
เราจะนำสมการ linear regression ไปแทนค่าใน x ของ logistic function ซึ่งค่าที่ได้ออกมาจะมีค่าระหว่าง 0,1 ทำให้สามารถทำนายแบบ classification ได้
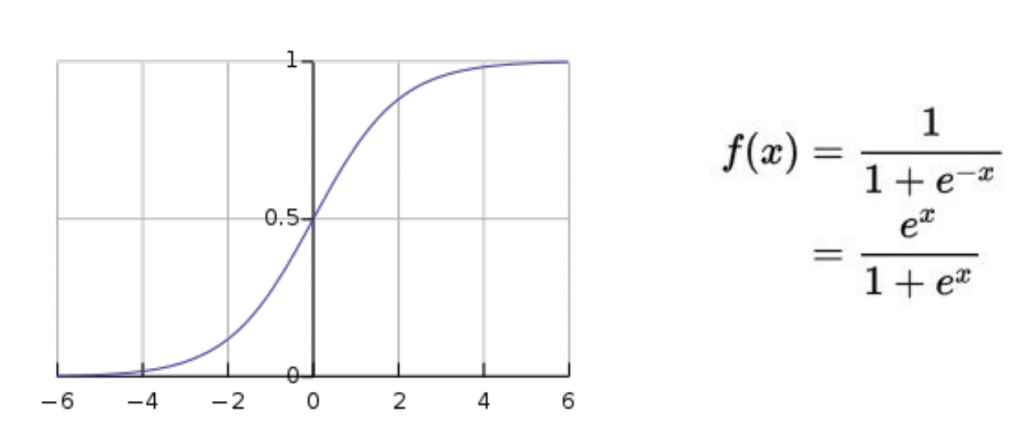
ซึ่ง model ที่ได้หลังจากแทนค่า x จะเรียกได้ว่า logistic regression

Quiz ช่วงเช้า

ภาคบ่าย
Clustering
clustering คือ การแบ่งแยกหรือจัดกลุ่ม โดยที่ข้อมูลไม่ได้กำหนดว่าเป็นข้อมูลประเภทอะไร เช่น การแบ่งกลุ่มจากพฤติกรรมของผู้ซื้อบ้านจัดสรร
เป็น Unsupervise learning คือ มีข้อมูล x มาให้ ไม่มีค่า y หรือไม่มีคำตอบ การใช้งานจะมีลักษณะแบบให้คนไปวิเคราะห์ต่อ เช่น การจัดกลุ่มลูกค้าว่ามีกี่ประเภท จัดกลุ่มเสียงพูดในห้องประชุมว่ามีคนพูดกี่คน จัดกลุ่มเพื่อนำไปใช้ต่อใน supervise learning
การแบ่งกลุ่มจะแบ่งได้หลายแบบ เช่น แบ่งตามพฤติกรรมของผู้บริโภคที่เหมือนกัน หรือแบ่งตามทำเลสถานที่ แบ่งตามราคา เป็นต้น



ในบางกรณีที่มีข้อมูลเยอะมากๆหรือใกล้เคียงกันมาก ไม่สามารถแบ่งกลุ่มได้จากการมองข้อมูล จึงต้องใช้คอมในการช่วยวิเคราะห์แบบอัตโนมัติ
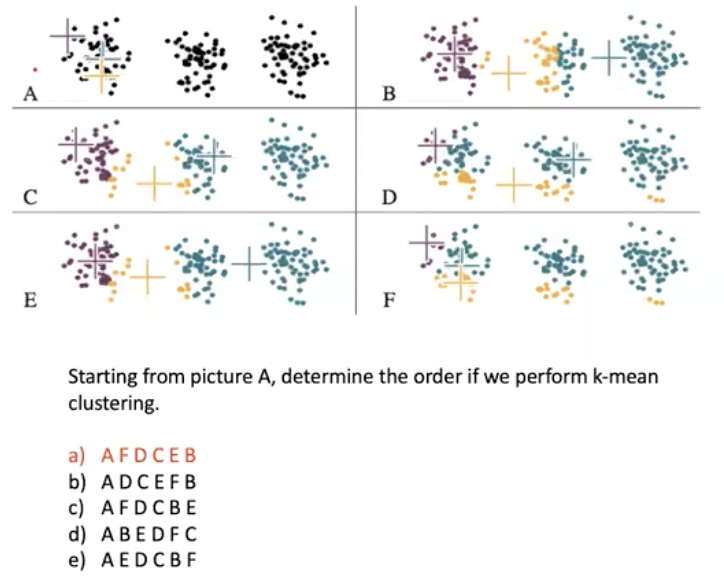
K-mean clustering
จะใช้วิธีการ Nearest Neighbour classification คือวิธีการหาเพื่อนบ้านที่ใกล้ที่สุด โดยจะหาจากทุกจุดและเปรียบเทียบกันว่าจุดไหนใกล้ที่สุด
วิธีการ K-mean
1.เลือกค่า K
2.สุ่มจุดกลาง (Centroid) เท่าจำนวน K
3.ให้แต่ละ Data Point เป็น Cluster ของแต่ละ Centroid ที่ใกล้ที่สุด
4.คิด Centroid ใหม่ ของแต่ละ Cluster
5.เปลี่ยน Data Point ตาม Centroid ใหม่
6.ทำซ้ำ 4-5 (Iteration) จนกว่าจะไม่มี Data Point ที่เปลี่ยนไป

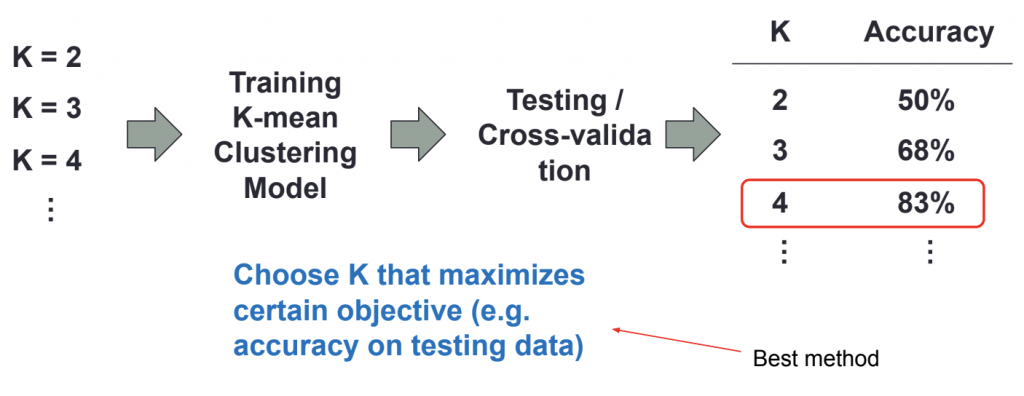
การเลือกค่า K
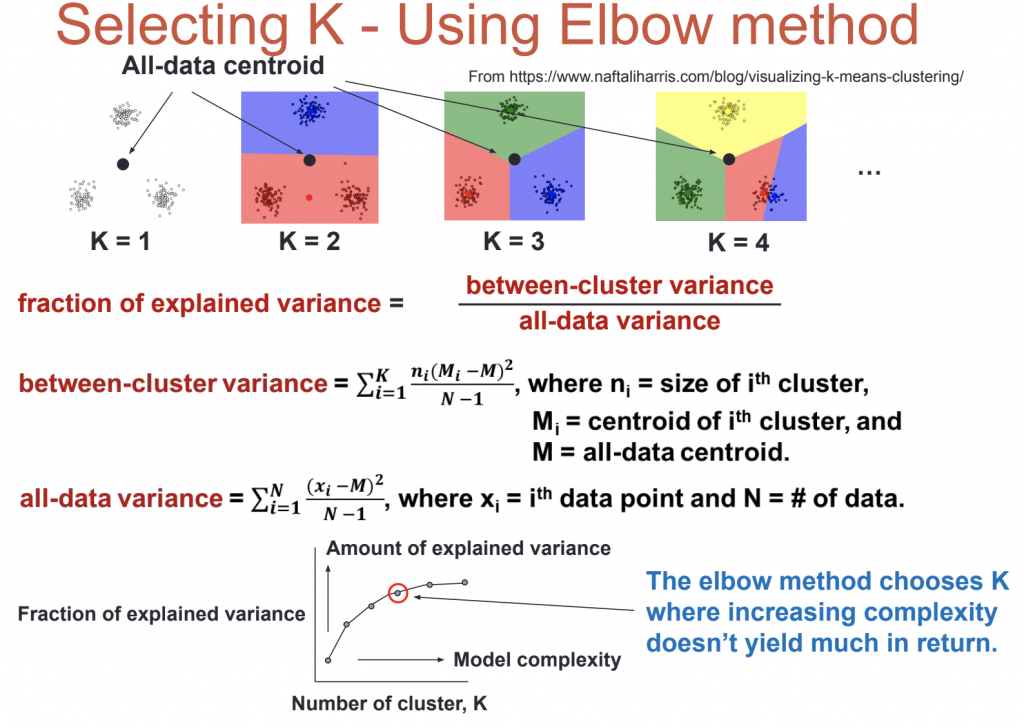
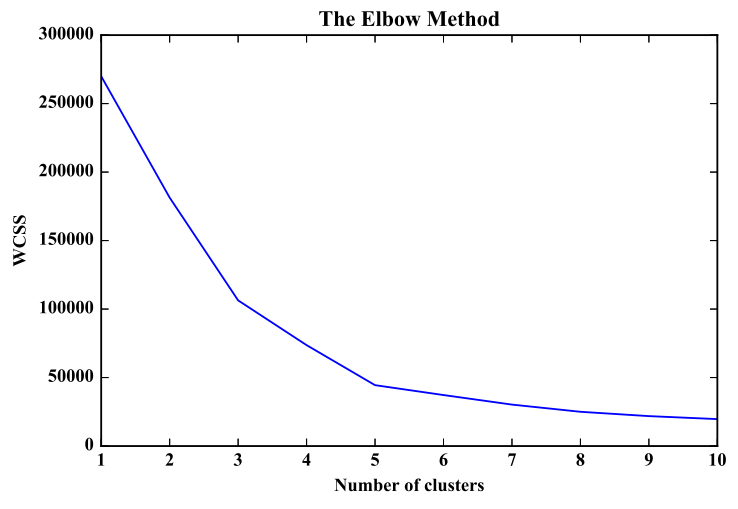
elbow method คือวิธีการวัด error ของผลรวมของระยะห่างระหว่าง object กับ centroid เรียกว่า Sum of square หรือ within-cluster-sum-of-squares (WCSS) จุดที่เหมาะสมของจำนวน Clusters คือจุดที่กราฟมีลักษณะหักมากที่สุด จากรูปข้างล่างจะเลือกใช้ k = 5 แต่การใช้งานจริงเราอาจจะเลือกใช้ 3,4 ก็ได้
อีกวิธีที่แนะนำว่าควรทำมากกว่า elbow method ทดสอบ k หลายๆตัว หา accuracy และเลือกใช้ตัวที่ได้ค่าดีที่สุด
Hierarchical clustering

Hierarchical Clustering คือ การวิเคราะห์กลุ่มแบบลำดับชั้นโดยขั้นตอนในการ cluster นั้นจะมีการแบ่งกลุ่มออกเป็น 2 กลุ่มโดยกลุ่มแรกคือ agglomerative clustering (จากล่างขึ้นบน) หรือ Divisive clustering (การแบ่งกลุ่มแบบแยก) โดยส่วนใหญ่เราจะใช้งานแบบ agglomerative จะมีการเชื่อมโยงข้อมูลคล้ายกับโครงสร้างต้นไม้
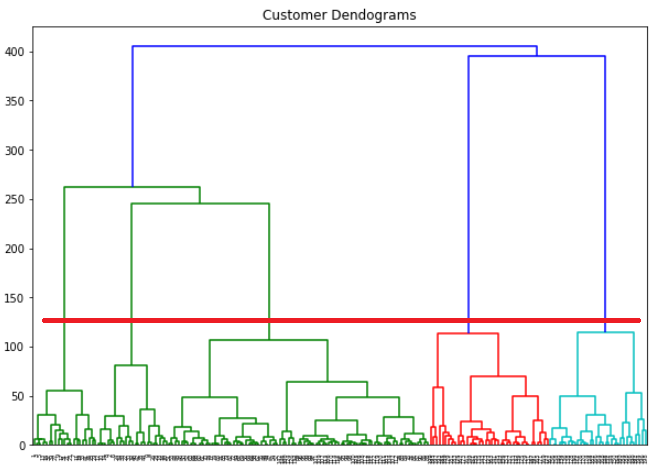
Dendogram
กราฟข้างล่างเรียกว่า dendogram ซึ่งใช้กับ Hierarchical Clustering จุดตัดเส้นแกนนอนกับแกนตั้งจะเป็นจำนวน K ซึ่งการพิจารณาวาดเส้นแกนนอนควรเลือกตัดเส้นที่ระยะแกนตั้งสูงที่สุด หรือแล้วแต่พิจารณา
K-NN Classification (Supervise Learning)
วิธีการ kNN จะกำหนดค่า k เมื่อ k คือจำนวนข้อมูลที่อยู่ใกล้ที่สุดกับข้อมูลใหม่ และ vote ว่าใกล้กับกลุ่มข้อมูลไหนมากที่สุดก็จัดเป็นกลุ่มนั้น กรณีที่ vote แล้วค่าได้เท่ากัน เช่น 2/2 เราก็พิจารณา vote จากระยะห่างด้วย โดยยิ่งห่างมากคะแนน vote ยิ่งน้อย เรียกว่า weighted k-NN
วิธีการ K-NN
1.นำข้อมูล Training มาพล็อตเป็นกราฟ
2.พล็อตข้อมูลที่ต้องการทำนาย
3.กำหนดค่า k (เรากำหนดเองได้)
4.นับจำนวนจุดที่ใกล้จุดที่ต้องการทำนายที่สุด k ตัวแรก
5.หาความน่าจะเป็นที่มากที่สุด จากเพื่อนบ้านรอบๆตัว
6.ใช้เสียงส่วนใหญ่ (Majority Vote)ทำนายผล

ระยะห่างหรือ distance หาได้จาก
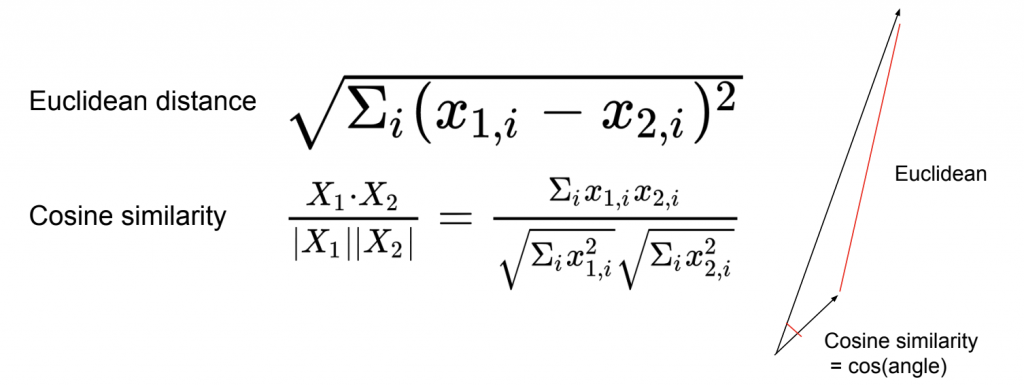
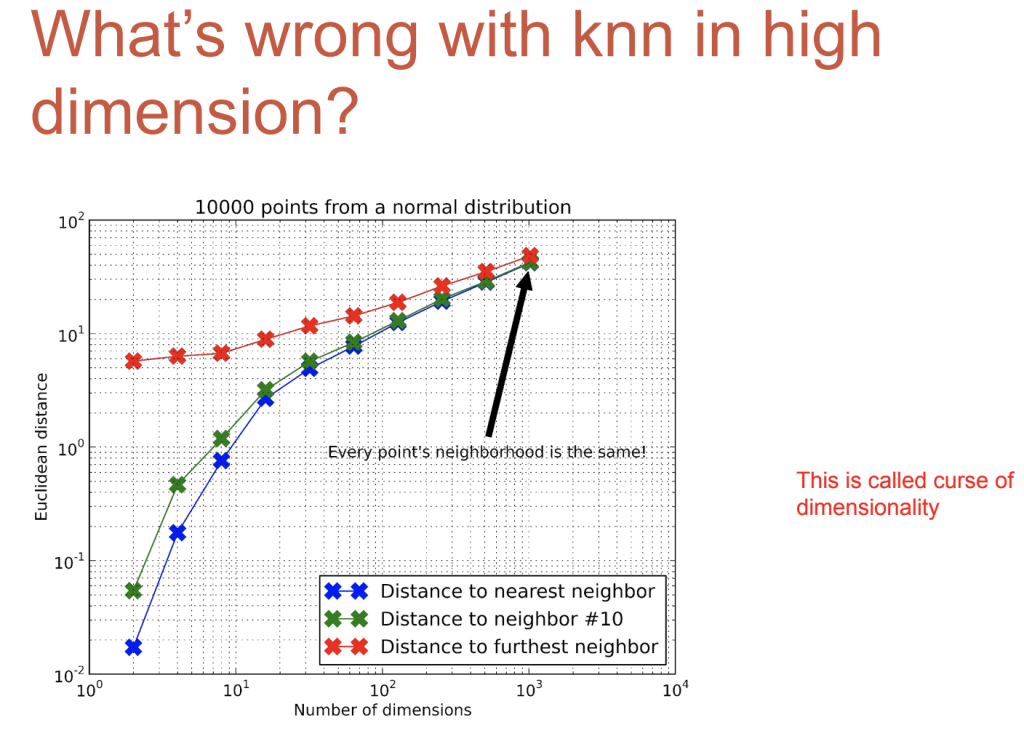
ข้อเสียของวิธี k-NN คือ ใช้ได้ดีกับข้อมูลที่มีมิติน้อยและ feature น้อย ยิ่งข้อมูลมีหลายมิติมากๆ distance จะใกล้เคียงกันมาก และทำงานได้ช้ากรณีที่มีข้อมูลเยอะๆ
การลดมิติข้อมูลเป็นวิธีที่ถูกนำเสนอเพื่อแก้ไขปัญหาของมิติข้อมูล curse of dimension ซึ่งได้รับผลกระทบจากข้อมูลที่ลักษณะ high dimension ที่ไม่มีการจัดการข้อมูลก่อนในเบื้องต้น ข้อมูลที่มีจำนวนมากนั้นมีลักษณะข้อมูลที่กระจัดกระจาย และบางข้อมูลไม่มีประโยชน์ในการวิเคราะห์ ซึ่งจะส่งผลกระทบต่อความถูกต้องของการประมวลผล และบางอัลกอริทึมไม่สามารถรองรับการทำงานของข้อมูลหรือตัวแปรจำนวนที่มากๆได้ นอกจากนี้ยังทำให้สิ้นเปลืองทรัพยากรในการประมวลผลอีกด้วย เช่น เวลาในการประมวผลนาน ใช้หน่วยความจำมากในประมวลผลแต่ละครั้ง ดังนั้นการออกแบบระบบการเรียนรู้ของเครื่องที่มีประสิทธิภาพจึงมีความจำเป็นที่ต้องมีการจัดการข้อมูลเบื้องต้นด้วยวิธีการลดมิติ
วิธีการลดมิติที่นิยมใช้ คือ เทคนิคการแปลงคุณลักษณะ (Feature Transformation) หรือเทคนิคการเลือกคุณลักษณะที่สำคัญ (Feature Selection) เพียงอย่างใดอย่างหนึ่งเท่านั้น
สรุป
เราจะทำให้โมเดลฉลาดได้ยังไง จากที่กล่าวมาแล้ว มีดังนี้
supervise มี x และ y ที่เป็นคำตอบ
unsupervise มีแต่ x ไม่มี label
semi supervise มีคำตอบเป็นบางส่วน วิธีการที่ใช้ เช่น transfer learning
reinforcement learning มีหุ่นยนต์ agent กับ environment โดยการเรียนรู้จากการกระทำ โดยมี reward เป็นตัวบอกผล
self-supervise learning
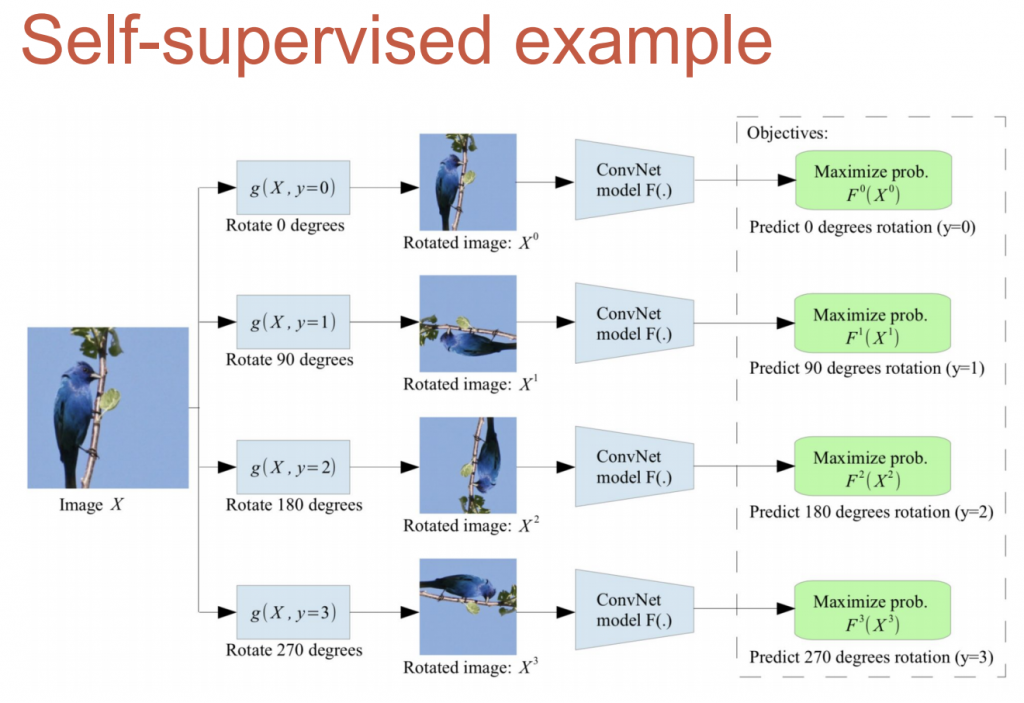
การสร้างข้อมูล โดย label ข้อมูลเองได้เลยเพราะทราบค่า target ตัวอย่าง เช่น ปรับรูปภาพหมุนหลายๆแบบ โดยที่แต่ล่ะแบบ เราทราบค่า target ของรูปนั้น
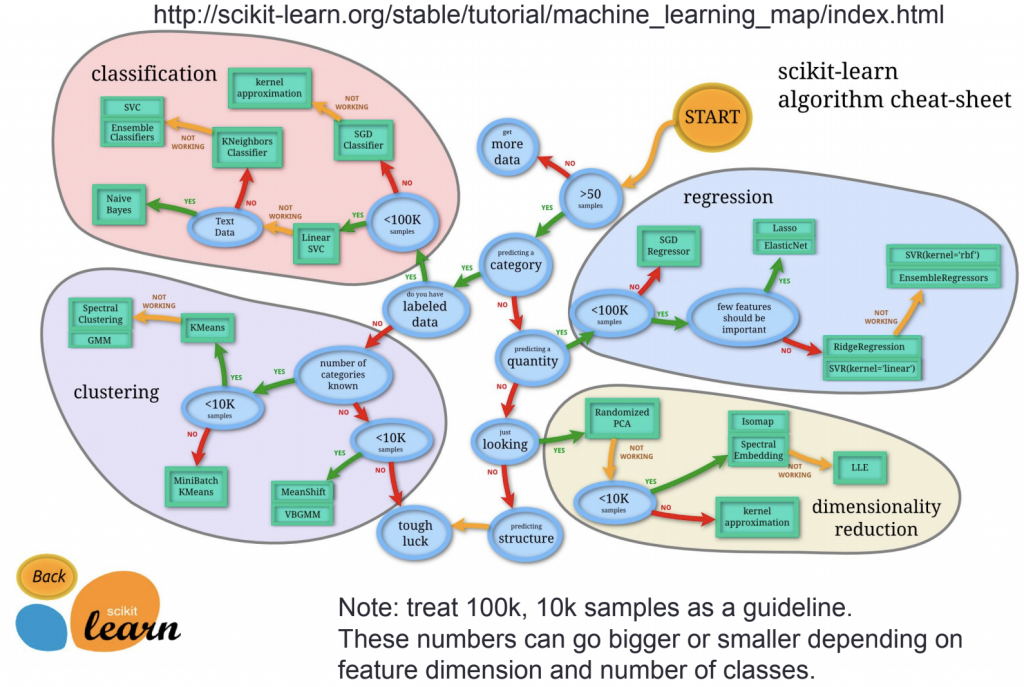
การเลือกใช้ model
ไม่มีโมเดลที่ดีที่สุดขึ้นอยู่กับหลายปัจจัย ดังนั้นต้องลองและวัดผล แต่จาก paper ที่ทำการทดสอบ random forest และ svm เหมาะที่สุด สำหรับข้อมูลที่น้อยกว่า 1,000
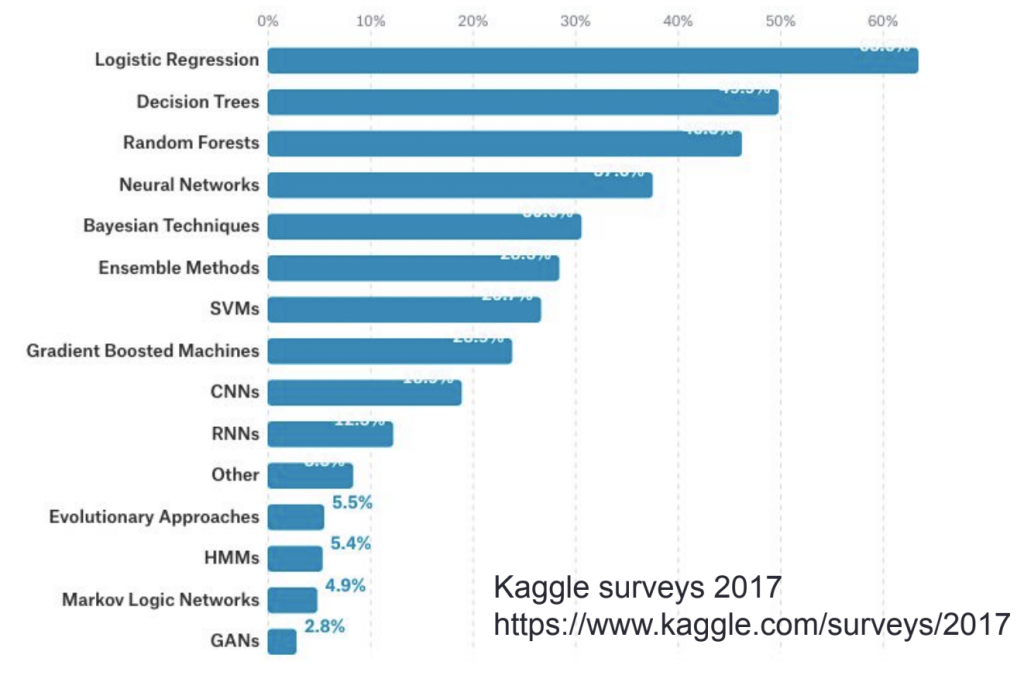
model ที่แนะนำ
Linear/Logistic regression Quick baseline เพื่อเป็นการลองโมเดลง่ายๆก่อน เพื่อให้รู้ว่า data ไม่มีข้อผิดพลาด และใช้ได้ดีกับ Text classification
k-NN เป็นพื้นฐานรูปแบบของวิธีอื่นๆ แต่ใช้ได้ไม่ดีกับข้อมูลขนาดใหญ่ ข้อดี class imbalance ไม่ค่อยมีผลกับ k-NN
XGboost,Catboost,lightGBM เป็นกลุ่มของ random forest ดีมากกับข้อมูล structure เช่น พวก excel(spreadsheet) ใช้ได้ดีกับ feature ที่เป็น categorical
Deep learning ใช้ได้กับข้อมูลที่เป็น unstruceture เช่น image,text,sound,time series
การพัฒนาโมเดล
เริ่มจากเตรียมข้อมูล โดยแบ่งเป็น 3 ส่วน
training set เอาไว้เรียน parameter
validation set หรือ dev set เอาไว้หา hyperparameter เช่น weight
test set ใช้วัดผลประสิทธิภาพ
ถ้าไปใช้งานจริง หา dev set,test setให้ตรงกับการใช้งาน โดยจะใช้สองข้อมูลนี้นำไปใช้พัฒนาโมเดล ตัวอย่างเช่น ถ้าต้องการให้ทายรูปว่าเป็นแมวหรือไม่ใช่แมว ข้อมูลควรจะเก็บมาจากรูปแมวที่ได้ใช้งานจริงๆ ไม่ใช่หามาจากแหล่งอื่น และ dev กับ test ต้องเกี่ยวข้องกับที่ได้ใช้งาน
วิธีการแก้ไข class imbalance
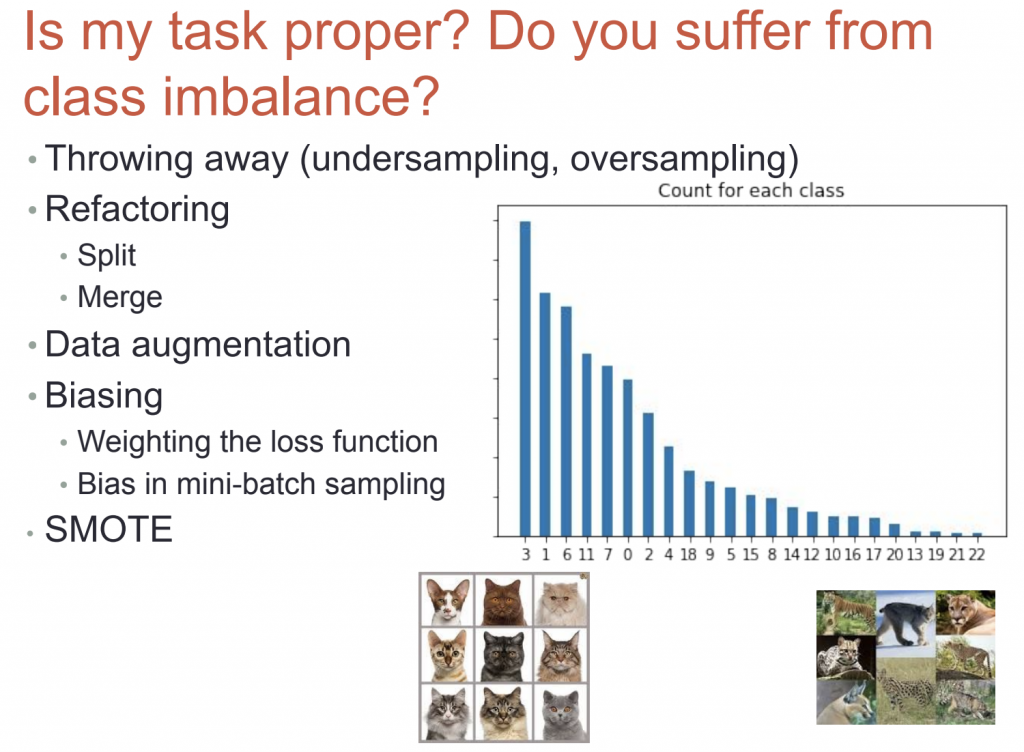
- undersampling ถ้า feature ไหนมีข้อมูลเยอะเกินให้ตัดทิ้ง
- oversampling คือ ก้อปปี้ข้อมูลวางเพิ่มต่อในข้อมูลเดิมให้มีขนาดเพิ่มขึ้น
- split หรือ merge เช่น การรวมคลาสเสือเป็นคลาสเดียว หรือแตกคลาสแมวให้ย่อยลงมา เช่น แมวดำ แมวขาว โดยต้องตกลงกับฝ่ายที่เกี่ยวข้องก่อน
- data augmentation นำภาพเดิมไปปรับแต่สี หมุนภาพ อื่นๆ เพื่อเพิ่มจำนวนข้อมูล
- biasing เช่น ปรับ weight ใน loss function โดยคลาสไหนที่มีข้อมูลน้อยก็ปรับ weight ให้มีค่ามาก
- smote การแก้ปัญหาความไม่สมดุลข้อมูล ด้วยวิธีการสังเคราะห์ข้อมูลใหม่
Bias Variance
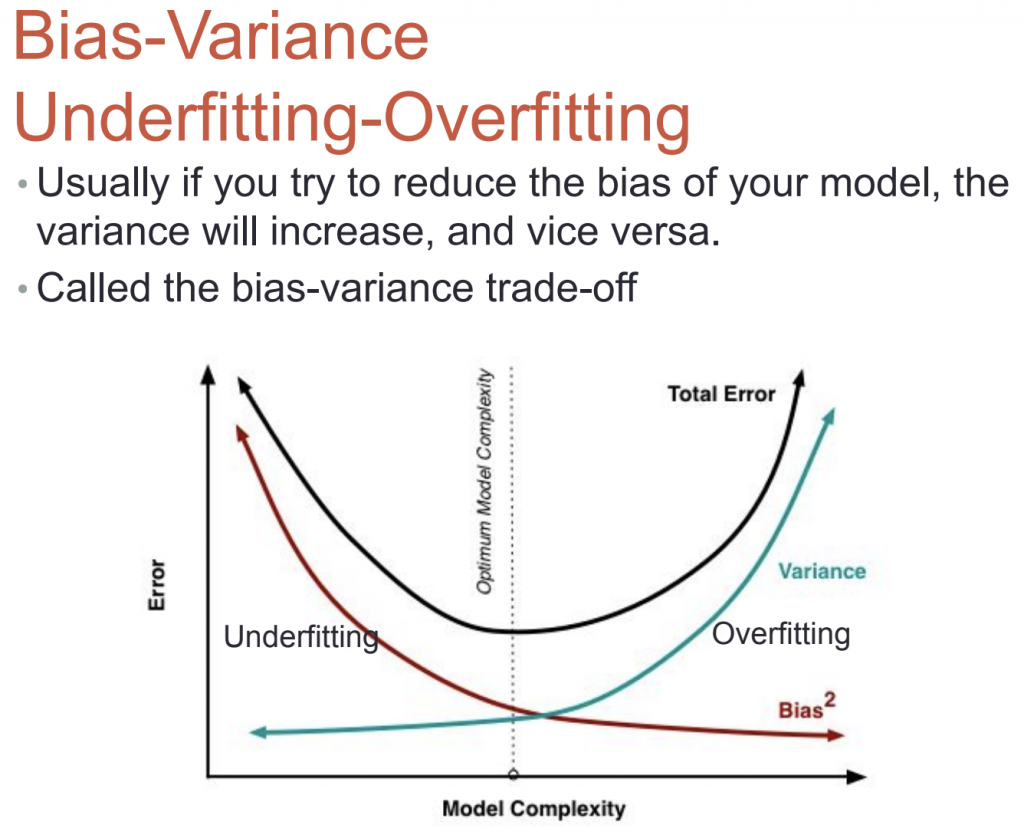
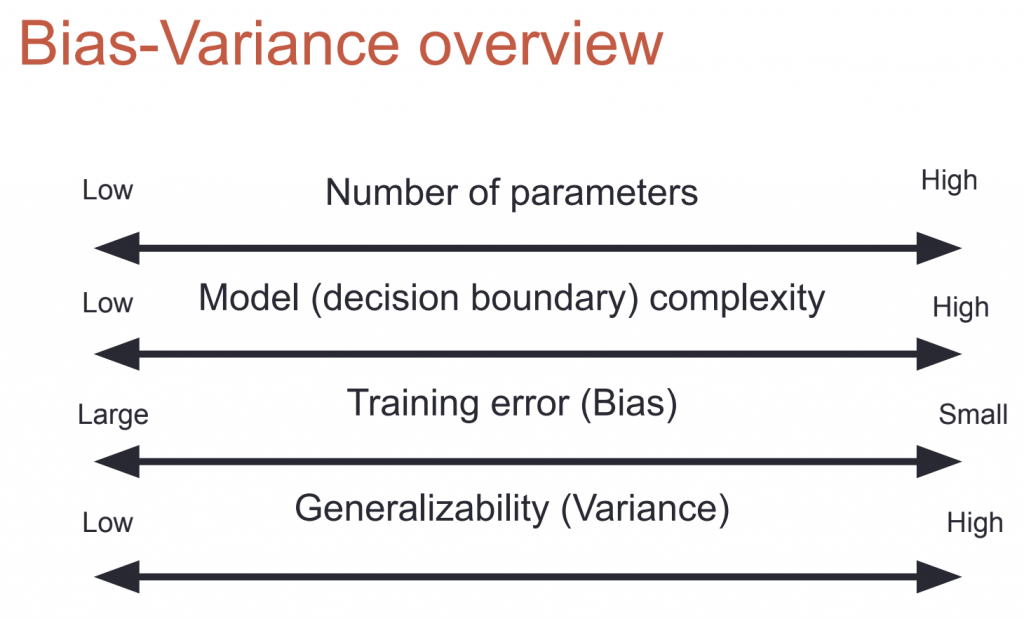
- overfitting (high variance) อาการคือ Training error มากกว่า test/dev error
- features น้อยเกินไป (high bias) อาการคือ Training error จะมีค่าสูง
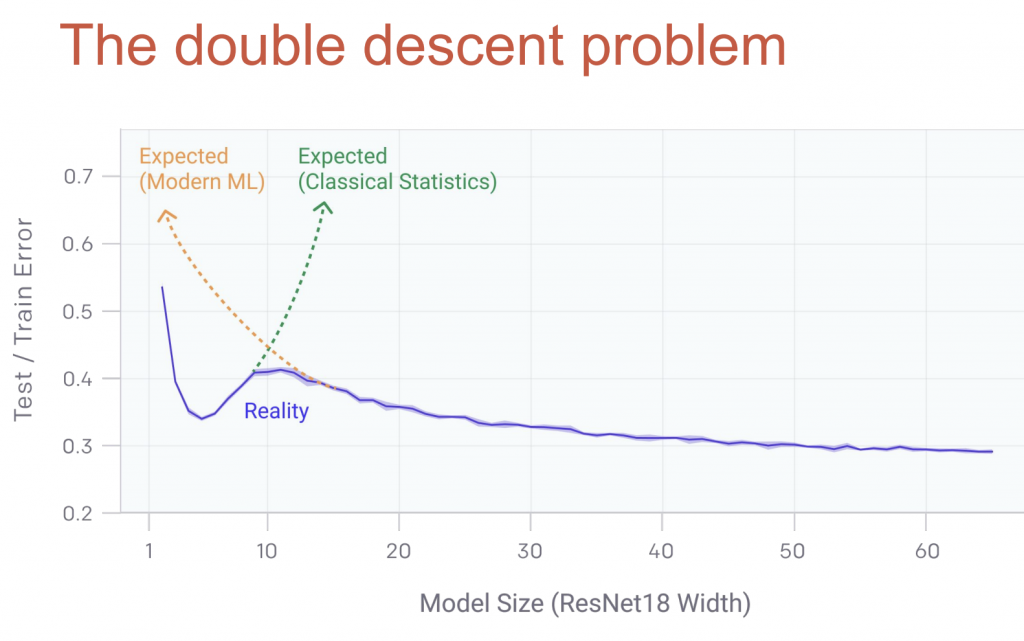
สมัยก่อนกราฟช่วงที่เป็น overfitting จะวิ่งขึ้น แต่ตอนนี้มีการพิสูจน์แล้วว่าในความเป็นจริงถ้า model ซับซ้อนมากขึ้นเรื่อย กราฟ error จะวิ่งขึ้นจนถึงจุดหนึ่งแล้วจะโค้งลดลงมา
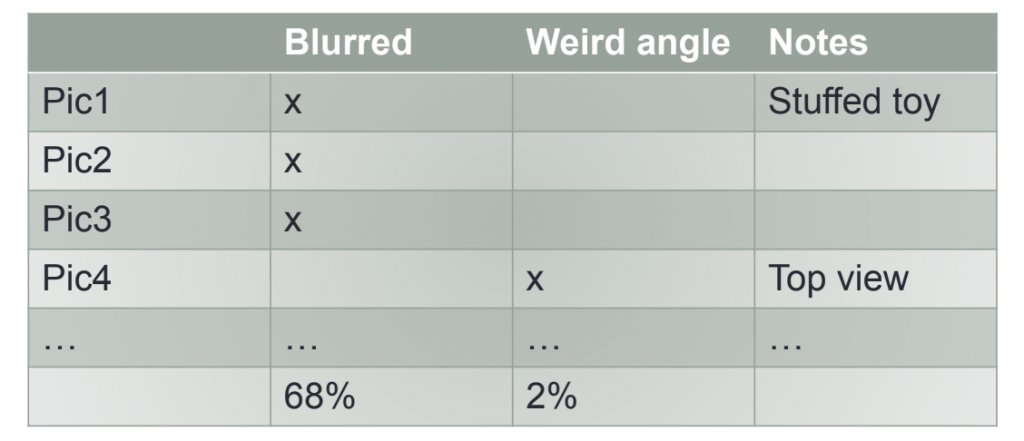
error diagnosis
ตรวจสอบดูว่าทำไมโมเดลทำนายข้อมูลผิด เช่น ในกรณีนี้ error จากภาพเบลอมากถึง 68% ดังนั้น ในกรณีเราควรจะแก้ไขภาพที่เบลอ
Quiz