สวัสดีครับ วันนี้จะมาเล่าถึงประสบการณ์ครั้งแรกกับการส่ง submit prediction กับเว็บ kaggle กับภารกิจหาผู้รอดชีวิตเรือ titanic ตามลิงค์นี้เลยครับ https://www.kaggle.com/c/titanic
เริ่มด้วยการอธิบายก่อนว่าเว็บ kaggle คืออะไร?
kaggle เป็นเว็บสำหรับทำการ prediction และการแข่งขันวิเคราะห์เพื่อหา model ที่ดีที่สุดสำหรับ dataset ที่บริษัทและบุคคลทั่วไปกำหนดมาให้ โดยจะมีทั้งโจทย์ที่ฟรีและบางโจทย์มีรางวัลด้วยนะ ประเด็นหลังนี่น่าสนใจเลยใช่มั้ยครับ
ดังนั้น kaggle จึงเป็นเหมือนสนามทดลองสำหรับคนที่อยากจะทำงานด้าน data science โดยสามารถลงทะเบียนเป็นผู้ใช้งานกับเว็บไซต์ หลังจากนั้นเราจะสามารถสร้าง kernel ได้ หรือก็คือเหมือนเป็น virtual machine ที่ใช้ในการประมวลผล data ต่างๆของเรา
โดยเสปคของ kernel มีรายละเอียดดังนี้
- 4 cpu
- แรม 16 gb
- disk space 1 gb
- ระยะเวลาประมวลผล 6 ชม.
- สามารถใช้ gpu ในการประมวลผลได้
- มี jupyter notebook ให้ใช้งาน
- สามารถเพิ่ม collaborator เข้ามาร่วมงานกันได้ ทั้งในส่วนของ kernel และ dataset
ส่วน dataset จะเป็นแบบ upload ที่เปิด “public” ให้พวกเราได้ลองวิเคราะห์กัน รวมถึง เราสามารถนำข้อมูลของเราเอง ขึ้นไปวิเคราะห์ก็ได้ โดยกำหนดให้เป็น “private” ก็ได้เช่นกัน
ชนิดของ dataset ประกอบด้วย
- csv
- json
- sqlite
- archieve
- bigquery
นอกจากนี้ ยังมีข้อมูลให้ศึกษาการเขียนโปรแกรมภาษา python, machine learning, pandas อื่นๆอีกมากมาย
เอาล่ะเมื่อรู้จัก kaggle แล้ว การร่วมลงภารกิจแรกของผมก็มาถึง ด้วยการค้นหาในเว็บ kaggle ว่าภารกิจไหนที่ผมน่าจะพอเริ่มต้นทำได้ บทสรุปก็มาตกที่ภารกิจหาผู้รอดชีวิตเรือ titanic ซึ่งเหมือนเค้าจะแนะนำกันสำหรับผู้หัดทำ data science นะครับ https://www.kaggle.com/c/titanic

โดยสิ่งที่โจทย์ให้มาจะมี
- training set (train.csv)
- test set (test.csv)
สิ่งที่ต้องส่งเป็นการ prediction ของไฟล์ test.csv ซึ่งเป้าหมายคือ จะเป็นการทำนายว่าบุคคลที่อยู่ในชุดข้อมูล test.csv นั้นจะรอดชีวิตจากการล่มของเรือไททานิคหรือไม่?
- ไฟล์.csv (418×2)
จากนั้นก็เริ่มลงมือทะเลาะกับข้อมูลได้เลยครับ โดยผมจะแบ่งเป็น 3 ขั้นตอนดังนี้
- สำรวจข้อมูล ดูข้อมูลข้างในและทำการวิเคราะห์
- ทำความสะอาดข้อมูล จัดการข้อมูลขยะต่างๆ
- สร้าง model ทดสอบ model ต่างๆเพื่อหา model ที่ได้ค่า accuracy สูงสุด
จากการค้นหาวิธีต่างๆและการลองผิดลองถูก จึงได้ผลออกมาและส่ง submit ไปเป็นที่เรียบร้อย ได้ผลดังนี้ครับ โดยหลังจากมีครั้งแรก ก็ต้องมีการปรับและลงครั้งต่อไป ตามนี้ครับ
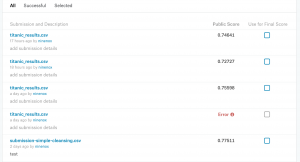
ซึ่งเลข score ที่ได้ก็เป็นคะแนนจากการทายผลของข้อมูลชุด test.csv นะครับ
ขอให้สนุกกับ data นะครับ.
1