Ninenox Developer
Menu
Blog
About
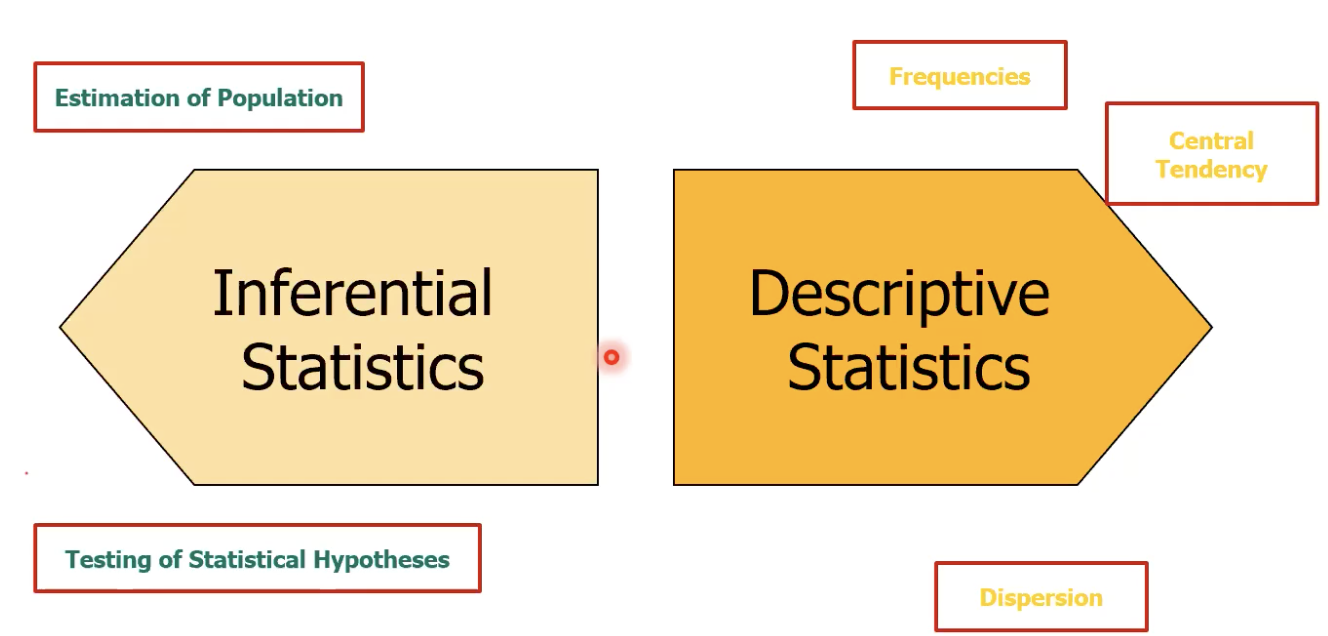
บทสรุป Hypothesis Testing
บทสรุป Hypothesis Testing
{kind=link}