
สวัสดีครับ ก่อนอื่นขอแนะนำตัวก่อนนะครับ ปัจจุบันผมทำงานอยู่ที่ บริษัท สมาร์ท เซนส์ อินดัสเตรียล ดีไซน์ จำกัด ลักษณะงานที่ทำส่วนใหญ่จะทำเกี่ยวกับด้าน Computer Vision วันนี้ได้มีโอกาสศึกษาการทำ Semantic Segmentation เพื่อคิดหาโปรเจคใหม่ๆให้กับบริษัท สิ่งนี้คืออะไร ในแง่ของการทำงานด้าน Computer Vision คือการหาวัตถุในรูปภาพที่เป็นชนิดเดียวและระบายสีวัตถุนั้นหรือแยกวัตถุต่างๆด้วยสีของ Pixel จากรูปข้างบนเป็นกรณีที่เป็นสองคลาส คือ รถยนต์กับไม่ใช่รถยนต์ ถ้าเป็นรถยนต์ก็จะทำการใส่สีเหลืองบนรถยนต์ หรืออาจจะแยกเป็นขาวดำก็ได้แล้วแต่การใช้งานของแต่ล่ะท่านได้เลยครับ
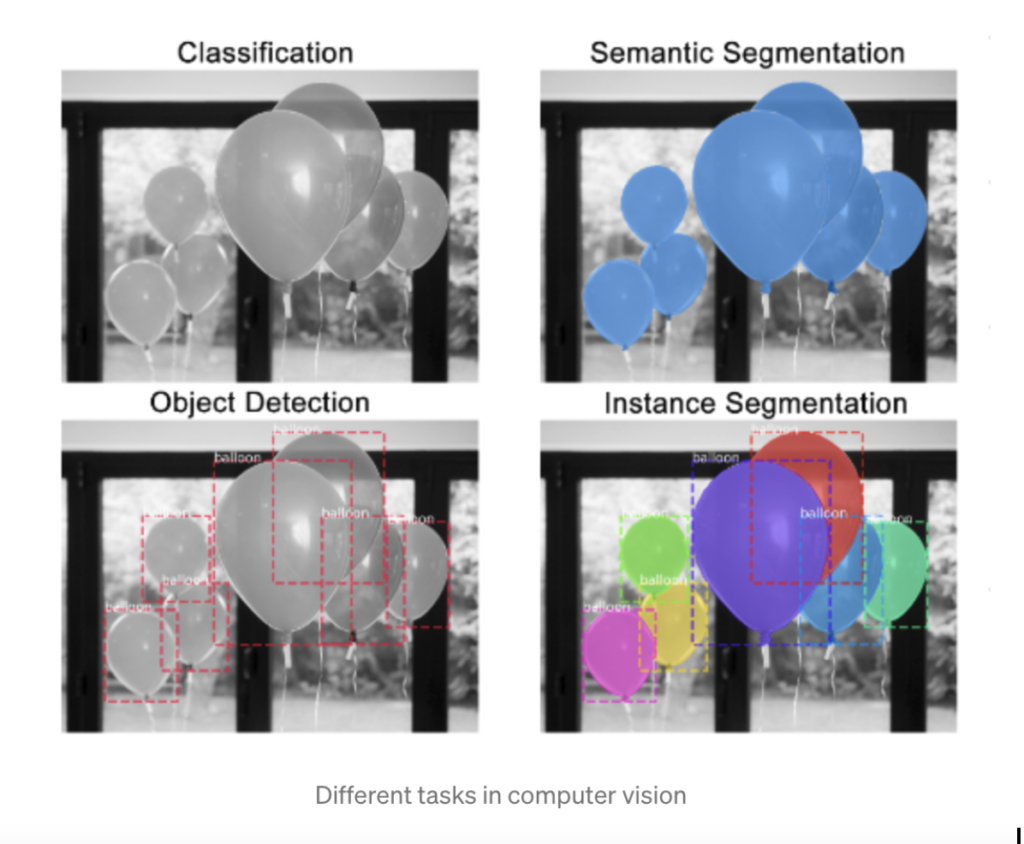
จากรูปภาพข้างบน เราจะเห็นว่างานด้าน computer vision เค้าแบ่งเป็น 4 แบบ คือ
- Classification วิธีการนี้จะมองทั้งภาพและพิจารณาว่าภาพนั้นเป็นอะไร
- Semantic Segmentation วิธีการนี้จะมอง Object เป็น Pixel โดยที่วัตถุเดียวกันจะมองเป็น pixel เดียวกัน
- Object Detection จะมอง Object ที่อยู่ในภาพและสร้าง Bounding Box รอบ Object นั้นและแสดงผลออกมา
- Instance Segmentation วิธีการนี้จะคล้ายข้อ 2. แต่จะเพิ่มตรง Object ชนิดเดียวกันแต่คนล่ะตัวจะมองว่าเป็นคนล่ะ Object
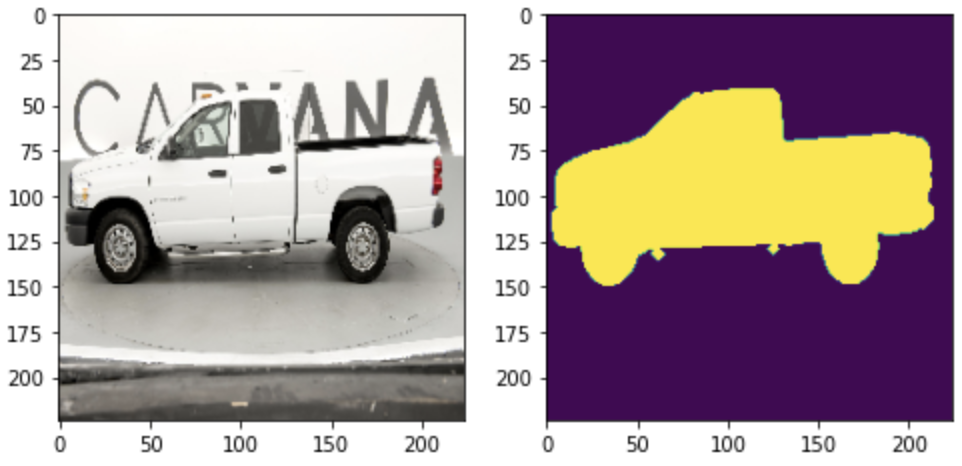
ส่วนที่ผมจะมาแชร์บทความให้ในบทความนี้ คือ ส่วนของการทำ Semantic Segmentation เริ่มจาก datasets ผมใช้รูปภาพของรถยนต์(ตัวอย่างของภาพรถยนต์ตามรูปด้านบน)ที่เอามาให้โมเดลเรียนรู้ทั้งหมด 484 ภาพ
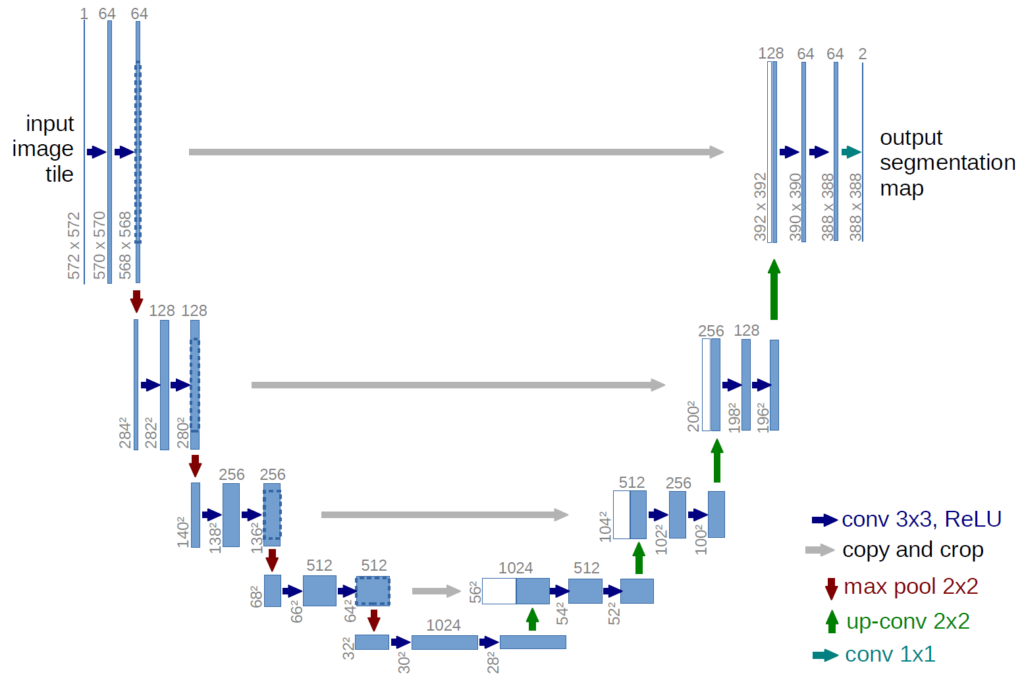
โดยอัลกอริทึมที่ใช้ คือ U-net จำนวนรอบในการ Train ใช้ 100 epoch
Epoch 100/100 10/10 [==============================] – 26s 3s/step – loss: 0.0034 – dice_coef: 0.9926 – accuracy: 0.9969 – val_loss: 0.0069 – val_dice_coef: 0.9847 – val_accuracy: 0.9933
จากนั้นทำการทดสอบรันกับวิดิโอ ได้ผลดังนี้
video: https://www.pexels.com
1